Как только человек изобрел компьютер, он стал
переносить в него свои знания. Поскольку главным носителем знаний до
появления компьютерной техники были книги, возникла задача - каким
образом накопленную информацию можно быстро перевести в "цифру"? Глупо
было бы использовать для этого самый простой и очевидный способ
перевода книг в цифровой формат - набор вручную. Человечество
тысячелетиями накапливало различные тексты, поэтому процесс их
повторного "написания" занял бы невероятно много времени. Для решения
этой задачи необходимо было найти какой-то простой и эффективный способ
автоматизации процесса повторного набора текста. Так возникли
различные технологии оптического распознавания текста или сокращенно
OCR (optical character recognition).
В наши дни с процедурой перевода машинописного листа в текстовый
документ знаком каждый студент и школьник. Печатный текст сканируется
(или фотографируется), затем с помощью специального программного
обеспечения компьютер анализирует снимок текста, выделяет на изображении
отдельные элементы и создает новый документ, в который заносит все
распознанные буквы и символы. Такой документ, как правило, является
редактируемым, благодаря чему можно исправлять ошибки машинного
распознавания и работать с ним как с набранным текстом.
В зависимости от сложности исходного текста и качества
отсканированного изображения, процесс обработки документа
OCR-приложением занимает больше или меньше времени. К счастью, сегодня
процедура перевода набранного текста в формат электронного документа
занимает намного меньше времени, чем несколько лет назад - аппаратные
возможности компьютеров за последние десять лет заметно увеличились, а
благодаря постоянным усовершенствованиям алгоритмов анализа изображения
процент ошибок стал намного меньше. Более того, теперь распознавание
текста можно доверить даже онлайновым сервисам, преимущества которых
перед обычными настольными приложениями очевидны - не нужно
раскошеливаться на дорогостоящее ПО и тратить время на установку
приложения. Наконец, используя для распознавания онлайновые средства,
можно получить редактируемый текст из снимка даже на таких компьютерах,
где просто нет возможности устанавливать программы, например, на
публичном ПК в библиотеке.
FineReader Online
Начнем с онлайнового сервиса компании ABBYY. Нет ничего удивительного
в том, что она использует в качестве системы для распознавания текста
популярную программу FineReader. В рекламе этот продукт не нуждается -
сегодня это приложение можно считать одним из лучших вариантов OCR.
Причин успешного продвижения этой программы очень много. Прежде
всего, это отшлифованный алгоритм идентификации печатных символов.
Движок самой популярной системы оптического распознавания текста,
FineReader, совершенствовался годами, механизм анализа изображения
улучшался от версии к версии. В программу вносились различные изменения
и улучшения, которые уменьшали количество нераспознанных или
некорректно определенных символов при обработке сканированного
изображения. FineReader включает в себя множество средств и
вспомогательных инструментов, которые дают возможность выполнить тонкую
настройку программы, улучшить качество исходного изображения,
определить тип распознаваемых символов, установить области для
обработки и т.д.
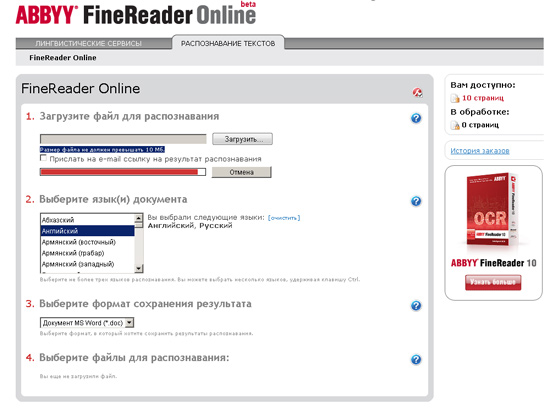
Онлайновый сервис является бесплатным проектом, который дает
возможность пользователям оценить точность работы FineReader. Одно из
его главных достоинств - поддержка большого количества определяемых
языков (всего доступно 37 языков). Для того чтобы воспользоваться
сервисом, необходимо пройти регистрацию. Поскольку этот проект носит
отчасти рекламный характер, возможности распознавания текста в нем
существенно ограничены.
Во-первых, анализ изображения происходит в полностью автоматическом
режиме. Пользователь может лишь указать язык распознавания и включить
опцию, которая позволит получить ссылку на результат распознавания на
введенный адрес электронной почты. Во-вторых, объем файла, загружаемого
на сервер, не должен превышать 10 мегабайт. Но самое неприятное
ограничение - небольшое количество документов, которое можно распознать.
Зайдя под одной учетной записью, можно обработать не более десяти
файлов. Однако и это, согласитесь, неплохо.
FineReader Online может также обрабатывать тексты, содержащие любые
комбинации поддерживаемых языков. При этом сервис не позволяет выбирать
более трех языков распознавания для одного документа. Разработчики
мотивируют это тем, что подобная функция существенно замедлила бы
процесс распознавания текста. Готовый результат распознавания текста
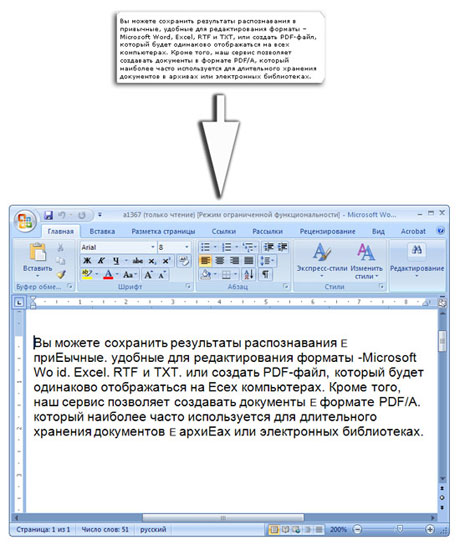
может быть сохранен в один из форматов - MS Word (.doc), MS Excel
(.xls), PDF, PDF/A, RTF и TXT.
В принципе, сервис справляется с поставленной задачей и определяет
текст. Однако, справедливости ради, следует сказать, что даже очень
хорошее качество исходного изображения не дает стопроцентной гарантии
распознавания. Даже такое "идеальное" изображение, как скриншот
всплывающей подсказки на странице сервиса, FineReader Online распознал с
ошибками.
ocrNow!
ocrNow! - британский сервис, который также использует в качестве
системы для распознавания текста FineReader. Уже на этапе регистрации
можно выбрать формат, в котором по умолчанию будут сохранены данные -
RTF, PDF, XLS, XLM, TXT или Web Archive. Изменить формат можно при
загрузке каждого нового файла. Кроме этого, есть возможность получить
текст по почте. Стоит отметить, что результаты могут быть запакованы в
ZIP-архив, благодаря чему время на загрузку полученного файла
сократится.
Сервис поддерживает загрузку изображений в форматах TIF, PNG и JPG
(JPEG), а также PDF. Кроме этого, можно загрузить ZIP-архивы, содержащие
файлы поддерживаемых типов, и они будут распакованы и обработаны
автоматически. ZIP-архив удобен не только тем, что позволяет уменьшить
размер файлов, которые необходимо загрузить на сервер, но и тем, что
благодаря ему можно загрузить несколько файлов за один раз.
ocrNow! работает с шестнадцатью языками, в том числе с документами на
русском английском, французском, чешском, испанском, итальянском.
Выбор языка осуществляется при загрузке файла. Даже если не указать
язык, сервис попытается определить его автоматически, правда, не
исключено, что он ошибется, поэтому лучше все же выбрать язык вручную.
Стоит заметить, что выбрать можно лишь один язык.
Каждому зарегистрированному пользователю предоставляется два
бесплатных кредита, которые можно использовать для распознавания двух
страниц формата A4. Если необходимо работать с большим
количеством данных, необходимо купить кредиты. Их стоимость зависит от
того, сколько кредитов вы решите приобрести за один раз. Например, если
купить 20 кредитов, то распознавание одного листа A4 обойдется в 0,1
фунта стерлингов (около 4,6 рубля), а если приобрести сразу 500, то
стоимость распознавания одного листа снизится примерно до 2,96 рубля.
Создатели сервиса предлагают специальную
утилиту, позволяющую использовать его совместно с Apple iPhone.
При помощи этой программы можно фотографировать документы, а затем
отсылать их на сервис и получать результаты. Бесплатная версия этой
программы дает возможность обработать десять фотографий, а коммерческий
вариант, снимающий это ограничение, обойдется в 14 долл.
Пользователям, которые часто обращаются к услугам сервиса со своего
настольного компьютера, предлагается скачать утилиту Unimessage Solo,
предназначенную для сканирования файлов. Особенность этой программы в
том, что в ней реализована интеграция с сервисом ocrNow! Кроме этого,
созданные с ее помощью файлы можно загрузить на Facebook.
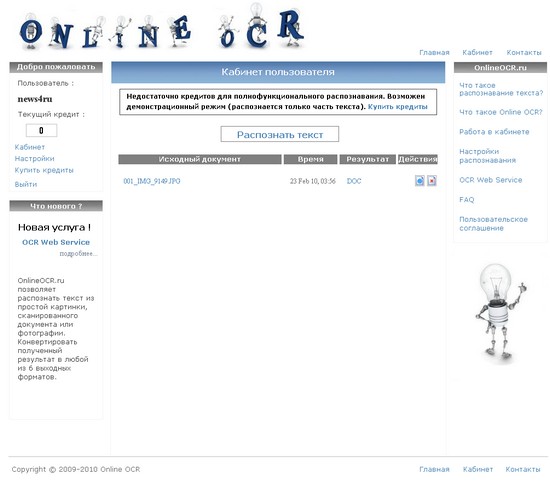
OnlineOCR.ru
Данный сервис является коммерческим. Для работы с ним необходимо
приобретать кредиты, каждый кредит - возможность распознавания одной
страницы документа. Однако даже в демонстрационном режиме с его помощью
можно переводить небольшие фрагменты текста.
Сервис предлагает очень удобную загрузку файлов - на сервер можно
загружать одновременно несколько изображений, упаковав их в ZIP-архив.
Максимальный размер файла - 20 мегабайт, но можно использовать и файлы
большего размера, однако для получения такой возможности необходимо
связаться с администрацией сервиса. В качестве исходного формата
графического файла можно использовать TIFF (поддерживаются в том числе и
многостраничные документы), JPEG/JPG, BMP, PCX, PNG, GIF, PDF.
Если с помощью данного сервиса распознается многостраничный документ,
например, PDF, можно указать только отдельные страницы для
распознавания. Для этого в настройках распознавания необходимо
установить флажок напротив "Многостраничный документ" и в поле для
диапазона страниц указать необходимые страницы через запятую (или
диапазон страниц через дефис). Если указать, скажем "4,13", сервис
распознает только четвертую и тринадцатую страницы.
В демонстрационном режиме сервис OnlineOCR.ru распознаёт не весь
текст, а только его часть. Всего сервис поддерживает 28 языков, включая
русский, английский, белорусский, венгерский, голландский, греческий,
датский, испанский, латвийский, латинский, немецкий, польский,
шведский, финский, французский, украинский и др. Сервис позволяет
хранить файлы с результатом распознавания в виртуальном рабочем
кабинете online, редактировать, отправлять их по почте и выводить на
печать.
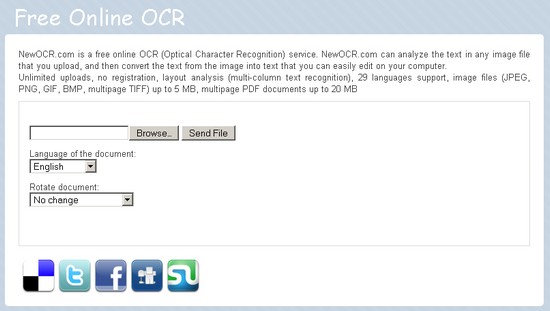
NewOCR.com
Проект NewOCR.com не требует ни регистрации, ни дополнительных
денежных трат со стороны пользователя. Сервис имеет минималистический
интерфейс, и его настройки сводятся к выбору языка. Если загруженное
изображение имеет неправильную ориентацию, например, повернуто в
процессе сканирования на 90 градусов, в выпадающем меню сервиса можно
установить угол поворота картинки. Качество обработки графического
файла оставляет желать лучшего - конечный документ содержит
многочисленные ошибки распознавания, поэтому вряд ли стоит использовать
этот сервис для обработки большого числа страниц. Этот недостаток
несколько смягчает то обстоятельство, что проект поддерживает работу с
29 языками (включая русский).
Распознавать можно изображения в форматах JPEG, PNG, GIF, BMP, а
также многостраничные файлы TIFF. Размер файлов не должен превышать
пять мегабайт, а для многостраничных PDF-документов лимит составляет 20
мегабайт.
После обработки отсканированного изображения сервис продемонстрирует
результат в отдельном поле, рядом с копией загруженного изображения.
Распознанный текст можно экспортировать в формат .doc или .txt.
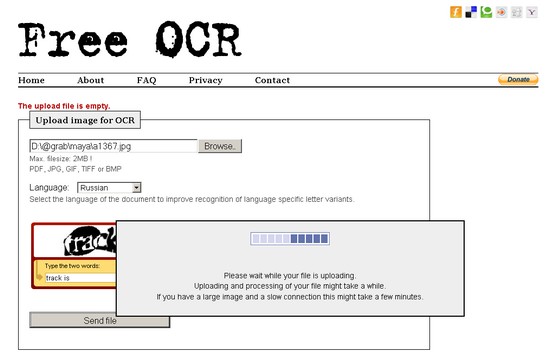
Free-OCR.com
Этот сервис можно использовать бесплатно, причем регистрация не
требуется. Для защиты от спама используется контрольное изображение
(Captcha).
Однако, выбрав этот сервис для обработки своих файлов, следует
учитывать ограничения, которые касаются обрабатываемых изображений.
Так, размер загружаемых на сервер файлов ограничен двумя мегабайтами.
Еще одно ограничение сервиса, которое касается загружаемых файлов, -
разрешение каждого из графических изображений не должно превышать 5000
точек по ширине. Кроме этого, Free-OCR.com устанавливает лимит на
количество обработанных документов. В час можно загрузить не более
десяти изображений.
На данный момент сервис не умеет распознавать многостраничные
документы PDF или TIFF, поэтому при обработке таких файлов распознается
только первая страница. Сервис позволяет обрабатывать страницы с
многочисленными столбцами текста. В настройках Free-OCR.com нельзя
выбрать более одного языка, поэтому, если попробовать распознать,
например, русский текст с английскими терминами, ошибок будет
предостаточно. Общее количество поддерживаемых языков, которые можно
выбирать для распознавания, довольно много - двадцать девять, в том
числе и русский. Качество распознавания документов удовлетворительное.
Заключение
Далеко не все услуги онлайновых сервисов для распознавания текста
предоставляются бесплатно. Однако цена, которую просят их создатели,
заметно ниже стоимости специализированного ПО. Естественно, если вам
необходимо распознавать десятки документов ежедневно, то платить
создателям онлайнового сервиса для вас вряд ли будет выгодно - гораздо
дешевле будет один раз заплатить за лицензию программы. Но если вы
пользуетесь подобными средствами лишь время от времени, то проще
заплатить за распознавание необходимого числа страниц или попытаться
обойтись полностью бесплатными сервисами.



















 Всего: 5499
Всего: 5499
